2026. 2. 22. 14:24ㆍJava/Basic
이 글에서는 Java로 코딩 테스트를 준비할 때 알아야 하는 Collection Framework의 구조와 핵심 개념을 살펴봅니다.
단순히 자료구조 사용법을 암기하기 보다, 각 자료구조가 어떤 계층에 속하고 어떤 특징을 가지는지 이해하는 것이 중요합니다.
이번 장에서는 다음 내용을 다룹니다.
- Java Collection Framework의 전체 구조
- Collection 계열과 Map 계열의 차이
- Iterable과 Iterator
- for-each 문이 동작하는 원리
- Map을 순회하는 방법
Java의 다양한 자료 구조
Java의 자료구조는 크게 두 계열로 나눌 수 있습니다.
- Collection 계열: 단일 요소들의 집합
- Map 계열: key-value 쌍의 집합
Map은 Collection 인터페이스를 상속하지 않으며 별도의 계층을 형성합니다.
이는 Map이 요소의 집합이 아니라 키-값 매핑 구조를 표현하기 때문입니다.

Java에서는 변수의 선언 타입에 따라 호출할 수 있는 메서드가 결정됩니다.
구현체를 사용하더라도 상위 인터페이스 타입으로 선언하면 해당 인터페이스에 정의된 메서드만 사용할 수 있습니다.
따라서 전체 계층 구조를 이해하고 있는 것이 중요합니다. 특히 코딩 테스트에서 코딩 테스트에서 자주 사용되는 구조는 반드시 이해하고 있어야 합니다.
전체적인 계층도는 다음과 같습니다.
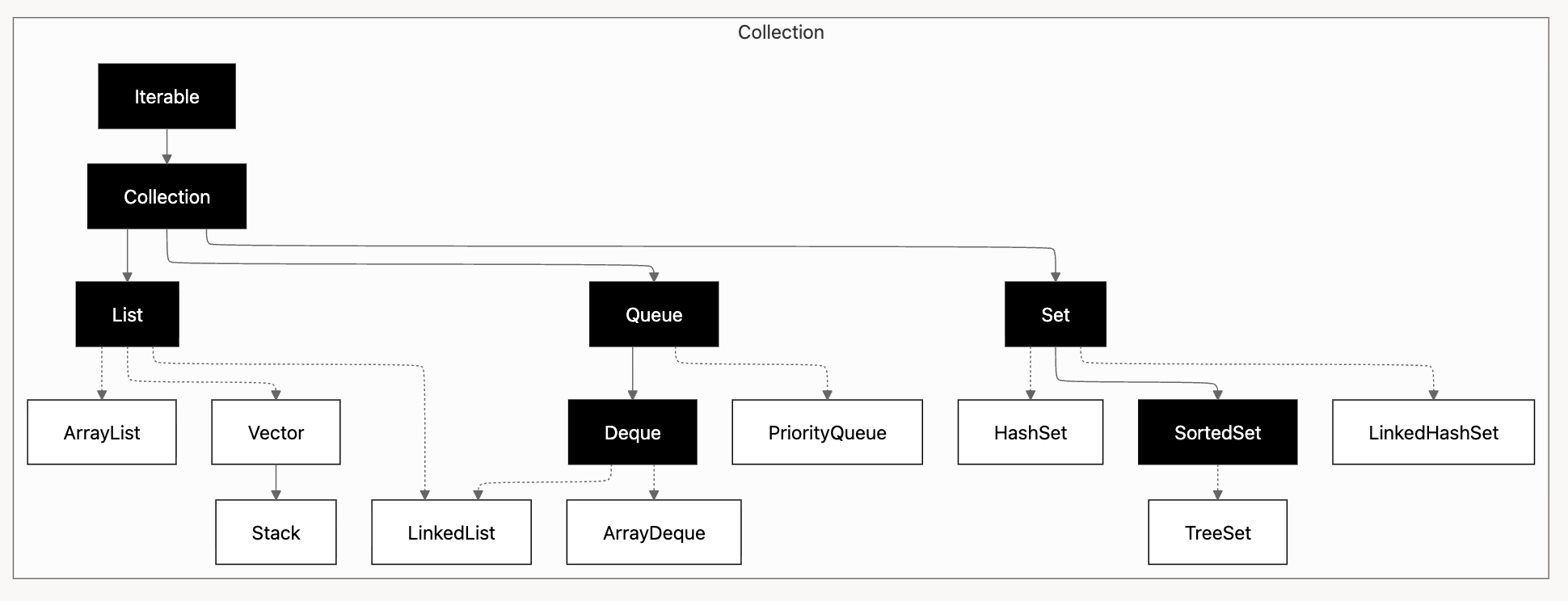

Iterable
Iterable은 Java에서 for-each문으로 순회할 수 있는 대상을 표현하는 인터페이스입니다.
공식 문서에서도 다음과 같이 설명합니다.
Implementing this interface allows an object to be the target of the enhanced for statement (sometimes called the "for-each loop" statement).
Collection Framework의 모든 컬렉션(List / Set / Queue 등)은 Iterable을 상속하므로 enhanced for statement(for-each loop)을 사용할 수 있습니다.
for (int x : List.of(1, 2, 3)) {
// x: 1, 2, 3
}활용
코딩 테스트에서는 자료구조를 순회하며 조건을 검사하거나 값을 누적·변환하는 요구사항이 매우 자주 등장합니다.
Collection 계열 자료구조는 모두 Iterable이므로, 자료구조의 종류와 상관없이 동일한 형태의 반복문을 사용할 수 있습니다.
예를 들어 List와 Set은 모두 Iterable이므로 아래 코드는 동일하게 동작합니다.
static int sum(Iterable<Integer> it) {
int s = 0;
for (int x : it) s += x;
return s;
}
Map은 왜 Iterable이 아닐까?
Map은 단일 요소의 집합이 아니라 key-value 매핑 구조이기 때문에 Iterable을 직접 구현하지 않습니다.
대신 다음과 같은 뷰(view)를 통해 순회할 수 있습니다.
- map.keySet() → Set<K>
- map.values() → Collection<V>
- map.entrySet() → Set<Map.Entry<K,V>>
이 반환값들은 모두 Iterable이므로 for-each loop를 사용할 수 있습니다.
for (Map.Entry<String, Integer> e : map.entrySet()) {
// key와 value 모두 접근 가능
}코딩 테스트에서는 key와 value를 모두 사용하는 경우도 존재하므로, entrySet()을 이용한 순회를 익혀두면 모든 상황에 대비할 수 있습니다.
Collection 순회하기
컬렉션 또는 맵의 요소를 순회하는 방법에 대해 알아보겠습니다.
enhanced for statement(for-each loop)
for-each loop는 내부적으로 Iterator를 사용하여 요소를 순회합니다.
동작 과정은 다음과 같습니다.
- iterator() 호출
- hasNext()로 다음 요소 존재 여부 확인
- next()로 요소 반환
즉, for-each 문은 다음과 같은 코드로 변환된다고 볼 수 있습니다.
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
int x = it.next();
}바이트코드로 확인하기
다음과 같은 코드가 있을 때,
for (int x : List.of(1, 2, 3));컴파일 후 바이트코드를 보면 실제로 Iterator를 호출하는 것을 확인할 수 있습니다.
15: invokeinterface #19, 1 // InterfaceMethod java/util/List.iterator:()Ljava/util/Iterator;
20: astore_1
21: aload_1
22: invokeinterface #23, 1 // InterfaceMethod java/util/Iterator.hasNext:()Z
27: ifeq 46
30: aload_1
31: invokeinterface #29, 1 // InterfaceMethod java/util/Iterator.next:()Ljava/lang/Object;
36: checkcast #8 // class java/lang/Integer
39: invokevirtual #33 // Method java/lang/Integer.intValue:()I
42: istore_2성능에 대한 오해
for-each loop는 코드가 간결해 경계 오류(IndexOutOfBoundsException)를 방지 및 자료 구조 내부 구조에 관계없이 동일하게 순회할 수 있습니다.
그러나 내부적으로 Iterator 객체를 생성하고 여러 메서드를 호출하므로 일반적인 인덱스 기반 for문보다 느려 보입니다.
실제로는 JVM의 최적화 덕분에 대부분의 상황에서 성능 차이는 거의 없으며, 코딩 테스트에서 사용하기에는 충분히 빠릅니다.
실제로 성능에 더 큰 영향을 주는 것은 반복문의 형태가 아니라 자료구조 자체의 특성입니다.
예를 들어 다음과 같은 선택은 반복문 종류보다 큰 성능 차이를 만듭니다.
- 배열 vs LinkedList
- ArrayList vs TreeSet
특히 LinkedList에서 인덱스 기반 접근은 $O(N)$이므로 반복문 전체가 $O(N^2)$이 될 수 있지만, for-each loop를 사용하면 Iterator 기반 순회가 이루어져 $O(N)$으로 처리됩니다.
따라서 코딩 테스트에서는 반복문 형태보다 적절한 자료구조 선택이 중요합니다.
forEach() 메서드
Java 8 (JDK 1.8)부터 Iterable에는 default 메서드인 forEach()가 추가되었습니다.
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}람다 표현식이나 메서드 참조와 함께 사용할 수 있습니다.
List.of(1, 2, 3).forEach(System.out::println);
/*
1
2
3
*/